
We have a monolith application hosted in Azure DevOps. We use the Pipelines product to run builds and tests on every pull request. After merging, the builds run again. Build times were creeping up towards an hour, leading to some pain points for our developers:
- It’s really frustrating to feel pressure to release a hotfix, but it takes multiple hours to prep a release artifact
- Even an insignificant code change due to PR feedback led to delaying the merge another hour
- Developers get distracted during builds and move on to new tickets, increasing work-in-process counts and delaying merges
I wanted to get it down to under 20 minutes. Here’s how we did it.
This app is a single git repo that builds and deploys several apps. We have a .NET Framework and .NET core backends for both the customer-facing site and an administration portal. There are also 3 front-end javascript apps to build using npm.
Historically we did this all sequentially across two separate pipeline stages:
- Stage: Build
- Build .NET solution which builds all four back-end apps
- Build & Test Front-End 1
- Build & Test Front-End 2
- Build & Test Front-End 3
- Stage: Test
Parallelism
The key to improving ADO build improvements is leveraging parallelization. To do that, you need concurrent jobs or stages.
Jobs can declare dependencies on other jobs. As soon as all their dependencies are finished, the ADO runner can kick them off. If you don’t declare any dependencies, then they will run in parallel, conditioned on your paid-for concurrent job settings.
This is key – if you want to leverage parallelization, you will have to give Microsoft some more money1. There’s a monthly fee for the additional parallel resources you consume. On the cheapest tier, you only get one concurrent job, so even if you structure your process to allow concurrency, you won’t actually get it. Fortunately, in our case, we were already paying for a handful concurrent jobs, but we seldom used them all.
I split the front-end builds out from the back-end compilation so that they were run in their own jobs. This lets us run the .NET build, and all three front-end builds simultaneously. Each build uploaded the build artifacts to artifact storage.
We then needed a job to take those artifacts and combine them: our deployment scenario needed the back-end and front-end deployments to be in the same zip file for upload to Azure App Services.
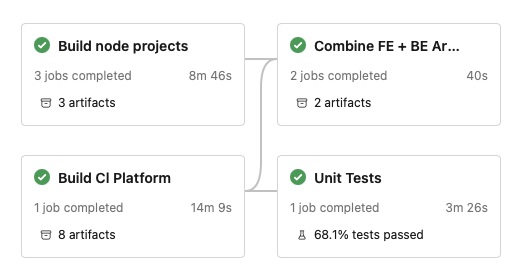
Build node projects runs three npm builds in parallel, each uploading its final artifacts to storage. Build Cl Platform compiles the back end .NET solution into multiple site deployment packages, then uploads those to artifact storage 2. Combine FE + BE Artifacts downloads all those artifacts and merges them together into packages that are ready to copy to Azure App Services.
This is a classic fork-join algorithm: we fork out and run all the builds in parallel, and when all of them are finished, join the results together in a final step. Sure, there’s some overhead in uploading and downloading temporary artifacts, but it’s minuscule (40 seconds) compared to the build times (8-15 minutes)
This, by far, had the biggest impact on overall build time: the first main stage only takes as long as the slowest build (the .NET backend, ~15 minutes).
Caching
Next, we could squeeze out a bit more performance by taking advantage of the Nuget and npm dependency caching. This computes a hash of your packages.config or package-lock.json files and uses it to restore a cache folder of downloaded dependency packages. This saved maybe 30-60 seconds on each of the concurrent builds.
If your dependencies don’t change often (and most don’t) you can really benefit from restoring a cache instead of resolving and downloading each dependency from the online repositories.
Linux
We also found that Linux build runners completed 15-25% faster than their Windows counterparts. I think Linux is generally better at disk IO and process forking, two features that the node ecosystem takes big advantage of.
We still needed Windows for the legacy .NET Full Framework builds, but since the front-end builds were switched out to their own jobs, it was trivial to mark them as using the ubuntu-latest virtual machine pool.
.NET Concurrent Build & Test
By default, msbuild doesn’t use multiple threads to compile your application. Neither does the Visual Studio test runner use multiple threads when running tests.
We got a few seconds of improvement by setting the .NET build job itself to use full threading by setting the maximumCpuCount property to true. This causes it to pass the /m flag to msbuild, which will spin up multiple build threads based on the number of CPU cores of the underlying machine.
Similarly, we set the runInParallel: true setting on the VSTest@2 task. This will also allow multiple threads to run the tests in parallel.
This didn’t make a huge difference; our solution structure doesn’t allow for too much parallelization, and I think the Windows runners are only 2 or 4 cores, so there’s not that much room for parallel CPU-bound work.
- https://learn.microsoft.com/en-us/azure/devops/pipelines/tasks/reference/msbuild-v1?view=azure-pipelines
- https://learn.microsoft.com/en-us/azure/devops/pipelines/tasks/reference/vstest-v2?view=azure-pipelines
Results

After these changes, we could consistently get builds to complete in 15-20 minutes, which meets my target.
- 1.Developer salaries will quickly outpace the cost of renting additional capacity. The cost for one extra unit of parallelization is currently $40 per month. A fully loaded developer cost in the US is easily over $100 per hour. Unfortunately, this is an argument to which many companies are immune. ↩
- 2.Honestly, theres no reason to use separate
Stageshere. At the time, I thought you could only specify thevmPoolat the stage level, but it looks like you can do it at the job level. I'll probably update it to be one stage with 4 parallel jobs instead of two stages, one with 3 jobs and the other with only one. ↩