Just look at this thing. I’m completely astounded at its capabilities.
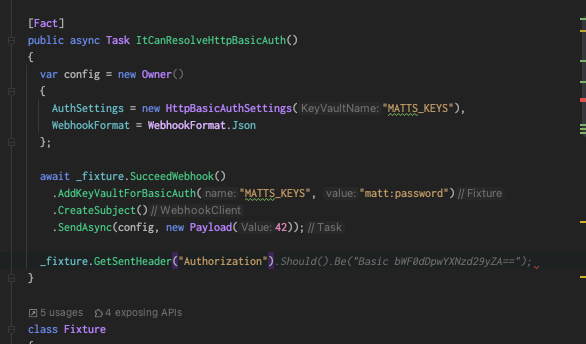
Most .NET developers are familiar with using the [Authorize] attribute on
their controller actions to specify access requirements for certain operations.
It’s often combined with a Role property to require the current user to belong
to a certain role. Recent versions of .NET and .NET Core introduced a Policy
authorization mechanism as well.
Instead of specifying a Role you can specify a required Policy. This is an
improvement because we can get a little more precise: an operation requires the
Read permission policy, not simply that the user belongs to the Admin role.
Flexibility! We can easily change what permissions are granted by each role, and
have very little code to change.
This all works pretty well for coarse permissions like “can this user read
things in general?” but it is insufficient for the more complicated case of
evaluating access to particular resources and entities in the system. Just
because the user is in the right role or group to grant them the ReadRecipe
permission doesn’t mean they have access to “this particular recipe”. Handling
rules like that requires a bit of custom code, but ASP.NET Core provides some
hooks that can help us make our business logic clear, without being too muddled
with authorization concerns.
What follows is a sketch of my approach to resource based authorization.
UPDATE: I’ve landed on my feet at Artisan Technology Group. Thank you to everyone who reached out with contacts and assistance.
I have greatly enjoyed my time at The Nerdery. Unfortunately, after 4+ years of service, the regional office where I worked was shut down.
For the first time in almost a decade I suddenly find myself out of work. I am immediately available for hire in senior or team lead positions in .NET or Javascript. While much of my career has been in consulting companies, I would also be interested to try working for a product company. In either type of role, one of my main interest is in getting opportunities to guide and mentor newer developers and help them level up their skills and careers.
If you are looking to fill roles similar to this, please get in contact with me at hello@mattburkedev.com. Further contact information can be found on my CV. See also my LinkedIn profile for additional detail and recommendations from my previous coworkers.
Processing uploaded files is a pretty common web app feature, especially in business scenarios. You frequently get a request from your users that they want to be able to do some work on some data in Excel, generate a CSV, and upload it into the system through your web application.
If files are small enough, or can be processed quickly, its generally fine to just handle the import within the request. But sometimes you have to do so much processing, or so much database IO that its impractical to run the import as part of the upload process: you need to push that work out to a background job of some sort.
If you’re allowing your user’s to log in to your website, its imperative that you protect their passwords with an appropriate hashing scheme.
Sometimes you need a little sitecore script to get something done real quick. If you’ve got it installed, you could reach for Sitecore powershell, and just use that, but I find the syntax obtuse and the lack of intellisense support to be limiting.
Usually what I do is just toss what I call a script page into the admin section, and use it.
Migrated this site to hexo as a static site generator. Its written for node, and performs much better for me than octopress.
Running ruby on windows was annoying to install, slow, and tough to maintain.
I wasn’t writing much because the workflow was so annoying. I had to run ruby in
bash for windows, use rake isolate to test a single article at a time, and
wait minutes for site re-generation.
Hexo generates the site in under 10 seconds.
I’ll be looking for a new non-default theme, but at least all the articles moved over without getting lost. Nothing important should be 404ing.
There’s probably some display quirks, but I’ve gone through all the posts and things looked mostly right.
Let me know if something is out of place.
Most of the time when I’m building a single page app, I want to use real URLS, rather than that hash-based nonsense that is generally the default. Most of the frameworks, (Angular.js, react-router, vue-router) refer to this url mode as “history” or “html5” mode. They use the relatively recent history API to push and pop URLs onto the browser’s navigation stack without incuring a full round trip to the server.
So you get nicer URLs like http://example.com/users/edit instead of
https://example.com/#/users/edit. I don’t like that hash mark.
The downside is that if the user saves a bookmark or sends a link to a friend,
the browser will actually request a resource at /users/edit (browsers don’t
send anything after # in a URL).
You need to configure the web server to respond to that URL by sending back the html shell that that SPA loads into, otherwise you probably get a 404, and no one likes that.
This is based on an email I send my .NET team at work
Happy Friday,
It appears to have been almost 2 months since I last sent one of these. My apologies for the laziness. I’m sure you wait every Friday with bated breath for a happy little notification in your email client.
Lets talk briefly about a few more new features in C#-7, which you can use today in VS2017.