We have an app we’re working on that has been experiencing some weird inconsistent latency spikes in Azure. It’s a .NET 6 (C#) REST API on a P1V2 Linux AppService and using Azure Health Data Services - FHIR API as the primary data store1. While this post discusses the Azure FHIR service, the findings apply to any third party HTTP service your app uses.
Load testing the app indicated really high latency spikes every couple of minutes. Most requests were well under a second response time, but after awhile it would spike up to over a minute, sometimes encountering socket timeouts. This was not even a particular big load test, just five users clicking on a listing page and then accessing the details page of a random item. Maybe 2-3 requests per second.

Azure AppInsights indicated the latency was coming from HTTP calls to the FHIR service. But visiting the portal page for the FHIR service revealed metrics graphs that did not show such a spike. Theres definitely something funny going on.
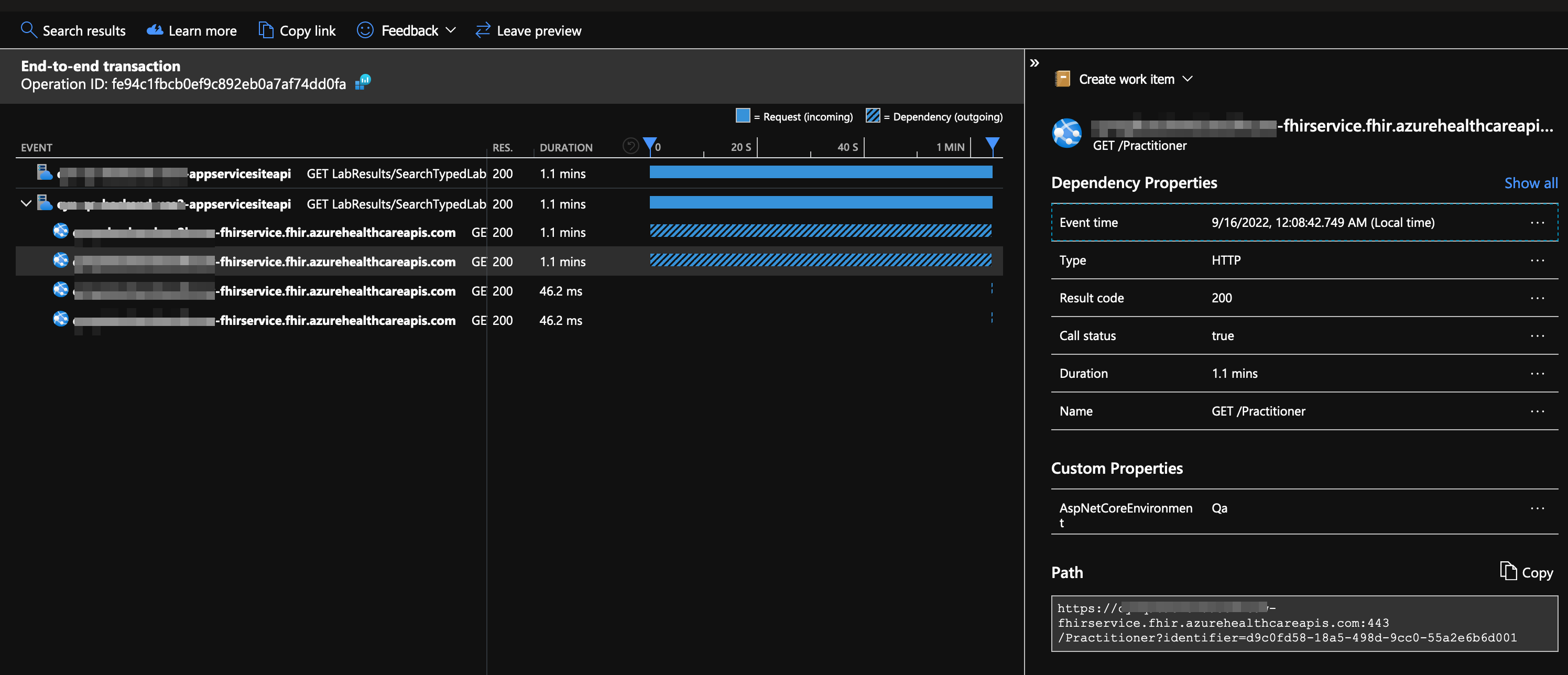
Running a load test directly against the FHIR API using the same scale did not exhibit any significant latency. This strongly pointed to the problem actually being rooted on the App Service side, not FHIR.
Turns out the app code was definitely doing something wrong. The open source
FhirClient library
news up HttpClient instances every request, which is a big no-no because it
keeps TCP connections open even after the client has been disposed. I was
vaguely aware of
guidance
that said this was bad but always figured it was only an issue at a much higher
scale.
However, Azure P1 services only have 1,920 ports for outgoing HTTP connection. If every request leaks a connection you can burn through those pretty fast even with just a half dozen users.
Luckily FhirClient has an overloaded constructor that lets you pass in an
HttpClient instance. Changing DI
registrations to use
IHttpClientFactory takes care of pooling the underlying socket resources.
After deploying this update, the load tests became much more consistent.

Another benefit of this fix was being able to reuse TCP connections to FHIR between requests. This provided a decent improvement in response times in addition to eliminating the port exhaustion issues.
Indicators of Port Exhaustion Problems in an App Service
- Spikes of latency
- SocketExceptions due to timeout
- Warnings in App Service Diagnostics
Azure provides some handy diagnostics in the portal for App Services that can clue you in if this is happening to your app.
Navigate to the portal page for your App Service and click in to “Diagnose and Solve Problems”. Check out the “SNAT Port Exhaustion” report and look for spikes indicating your app ran out of ports for outgoing TCP connections.
During the load test window, Azure showed this:
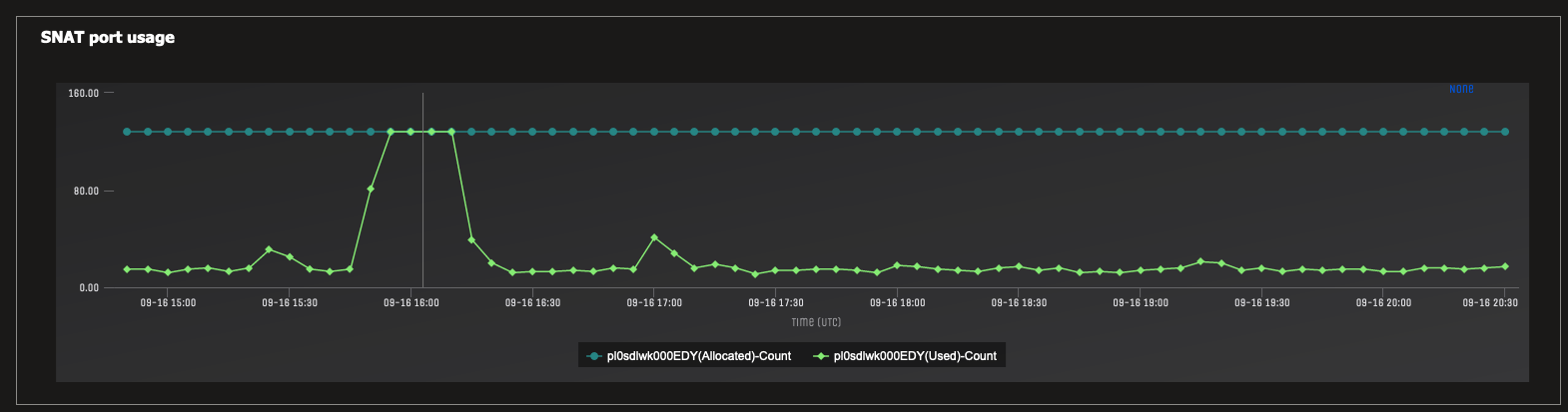
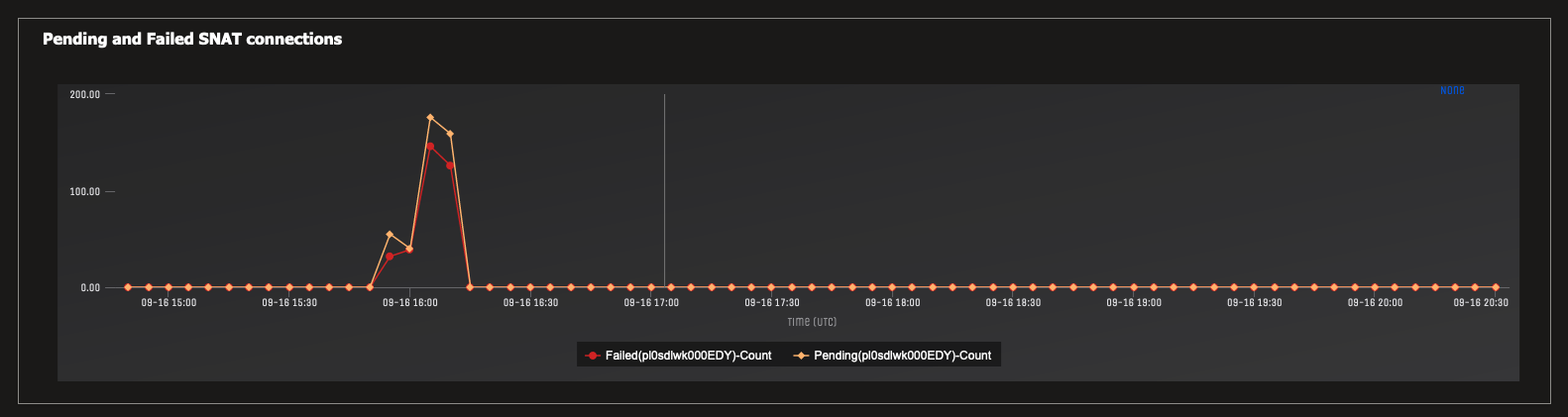
Key Take Aways
- Port exhaustion can kill your app even at low scale. Take the guidance seriously, especially if your app makes outgoing HTTP calls to service most requests
- If you’re building a library that wraps
HttpClient, be sure to have a constructor that lets your users inject theHttpClientinstance so they can use pooling - Relatedly, if you’re using a third party REST API and the provider ships a
nuget package for accessing it, look into its source code to see if it’s
pooling
HttpClientor if it allows you to inject your ownHttpClient - AppInsights dependency tracking includes connection time and queueing waiting for an open socket. High latency in AppInsights reports is not proof that a third party is failing to meet its SLAs, it might be your side
- Symptoms of port exhaustion include increased or random latency and
SocketExceptions or timeouts - Azure has some really good troubleshooting tools you can benefit from to see if this is happening to you
- You can get ~25% improvements from reusing TCP connections via
IHttpClientFactory
Further Reading
- https://docs.microsoft.com/en-us/azure/architecture/antipatterns/improper-instantiation/#how-to-fix-the-problem
- https://docs.microsoft.com/en-us/azure/app-service/troubleshoot-intermittent-outbound-connection-errors
- https://docs.microsoft.com/en-us/dotnet/architecture/microservices/implement-resilient-applications/use-httpclientfactory-to-implement-resilient-http-requests
- https://www.aspnetmonsters.com/2016/08/2016-08-27-httpclientwrong/
- https://github.com/FirelyTeam/firely-net-sdk/issues/2036
- https://docs.fire.ly/projects/Firely-NET-SDK/client/setup.html
- https://azure.github.io/AppService/2018/03/01/Deep-Dive-into-TCP-Connections-in-App-Service-Diagnostics.html
- How to Correctly Register FhirClient for Depedendency Injection
- 1.FHIR is a data interchange standard for healthcare data. Conforming implementations all use the same resources, properties, and querying capabilities ↩