The hackernewsletter today linked to the Wikipedia article on Benford’s Law, which is a rather interesting topic.
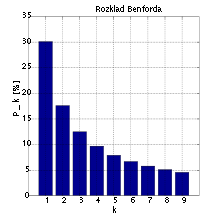 Benford’s Law holds that in many common data sets, the distribution
of the first digit of each member of the set forms a gentle curve, wherein
about 30% of the numbers start with the digit 1 down to about 5% starting with
0.
Benford’s Law holds that in many common data sets, the distribution
of the first digit of each member of the set forms a gentle curve, wherein
about 30% of the numbers start with the digit 1 down to about 5% starting with
0.
I was curious to see what other data sets might fit within this distribution.
Just a few ruby scripts away!
Ruby’s Random Number Generator
Like a good PRNG, ruby’s rand method returns numbers that are fairly evenly
distributed over the output range.
1 | [15:11:42 mburke]$ ruby benford.rb random |
Length of English Words
I also tried the length of English words found in the Mac’s default
/usr/share/dict/words file
1 | [14:53:02 mburke]$ ruby benford.rb words |
Since almost all words are less than 20 letters, its not surprising that the majority of them fall between 10 and 19 letters long.
Lines in Main Source Code Folder
I calculated the number of lines in each of the files in our main source code repository. This data set did rather closely follow the expected distribution.
1 | [15:02:20 mburke]$ find . -type f -exec wc -l {} \; | cut -d " " -f 1 > ~/Desktop/source-lengths.txt |
Twitter Stats
Using the awesome t gem, I calculated the Benford distribution for the number of followers, following, and tweets of the people I follow on twitter.
1 | [22:16:04 mburke]$ t leaders | xargs t users --csv -l >> leaders.csv |
1 | [22:49:21 mburke]$ ruby ~/personal/ruby/benford.rb file <(tail -n+1 leaders.csv | csvfix order -f 4 | sed 's/\"//g' ) |
1 | [22:50:52 mburke]$ ruby ~/personal/ruby/benford.rb file <(tail -n+1 leaders.csv | csvfix order -f 7 | sed 's/\"//g' ) |
1 | [22:51:28 mburke]$ ruby ~/personal/ruby/benford.rb file <(tail -n+1 leaders.csv | csvfix order -f 8 | sed 's/\"//g' ) |
Nothing in these sets followed Benford’s Law perfectly, though they at least have the gradual drop off as the first digits grows.
Perhaps a bigger data set would converge better.
I’ll update this as I think of more sets to try.